CI/CD is one of the most widely used modern software engineering practices. Companies use CI/CD pipelines to unblock developers by automatically building, testing, and deploying their code changes. However, with access to your code, internal systems, and secrets, your pipelines are a valuable target for malicious actors.
As an engineer managing CI/CD, there are a lot of potential security controls to consider. In physical security, these controls include walls, locked doors, and guards—in CI/CD, we instead define security boundaries with hardware and software configurations.
We've already talked about how compliance and governance can secure your CI/CD system, and some common security vulnerabilities. But in this post we’ll review several important threat types and how to address those by setting boundaries.
Definitions
Here are some of the terms we’ll use in this post:
- Pipeline: A workflow to run.
- Agent: A build runner that executes a pipeline.
- Cluster: An isolated set of agents and pipelines.
- Queue: A pool of related agents inside a cluster.
But don't worry if those look complex. We'll explain these terms more when they come up.
Risks for CI/CD systems
First, we’ll discuss some common CI/CD risks you should be aware of, including ways your systems could be compromised and run afoul of sensitivity or regulatory issues.
Identity and access
Adding, removing, and editing users are common tasks for anyone managing tools—we’re no strangers to the process. Regardless, it’s worth revisiting the basics, starting with having visibility and a process to regularly audit who and which accounts have access to what.
The principle of least privilege is a useful place to begin. That means limiting access to data, code repositories, and pipelines based on what each account needs. Ideally, you can look at an account’s access and have a good understanding of what it does. For example, an account with access to just the site and ui repository is likely used by a frontend developer.
Investigate how your tools can allow granular access, and use this knowledge when assigning permissions. For example, can you set read/write access on a per-pipeline level, or does access to a code repository mean full control over that repository’s pipelines?
You should also consider whether access is needed at all. For example, access to the main ops repository may not be necessary if the engineer could get the same benefit from seeing architecture and process diagrams shared elsewhere.
De-provisioning can be even more important than assigning access. We’ve all heard stories of developers retaining access weeks after leaving a company, which can expose your organization to many risks. You might solve this with processes, such as:
- Using automation or infrastructure-as-code to revoke access to all tools and infrastructure in a single step.
- Using single sign-on to revoke CI/CD access when a user’s code repository access is revoked.
- Confirming access is revoked in the employee off-boarding process.
As with anything related to security, there’s a balance between convenience and safety. But it’s a fact that the more access is restricted, the less damage an attacker can do with a single compromised account. With account management practices like single sign-on and granular permissions, it’s possible to give strictly the access that’s needed, and no more.
Maintaining open-source projects
Open-source projects are a fantastic way to give back to the community, collaborate, and let your team’s skills be seen by others. But for CI/CD, there are unique risks you’ll need to keep in mind.
It’s common to have test suites run on untrusted changes for new/edited PRs, and to deploy new builds when code is committed to certain branches. If pipeline definitions also live in the code repository, contributors can modify both those definitions and the commands run by them. These edited pipelines can list secrets or use access in a different way than intended. This is called a poisoned pipeline execution attack, and it can be launched by both trusted contributors (committing changes to new branches) and public contributors (submitting PRs).
Potential mitigations for this type of attack include:
- Move pipeline definitions outside of the code repository.
- Keep secrets and access away from publicly editable pipelines.
- Restrict code repository access.
- Enable branch protections.
- Restrict pipeline runs from third-party changes (for example, Buildkite lets you configure whether to run pipelines on PRs from third-party forks).
You should also pay attention to common software security issues like typosquatting and contributors submitting malicious or buggy code.
The security issues and attacks described here can certainly happen if your code repository is restricted to trusted internal contributors. But it’s important to note that opening your projects to public contributors makes it possible for anyone in the world to submit changes, and depending on where the CI/CD runs and what access it has, those changes can affect your internal systems and infrastructure. This is why it’s important to create security boundaries and enforce a zero trust policy around potentially-untrusted code and services.
Sensitivity and regulations
Pipelines perform actions and may interact with sensitive data, endpoints, codebases, and more. Depending on the sensitivity and access needed, the agents running those pipelines may have special requirements.
For example:
- The agents may need to run on-premises inside your security perimeter, or in particular regions if hosted on a cloud-based service.
- The agents may need IP-based access to parts of your internal or external infrastructure.
- The hosts running agents may need to comply with particular regulatory needs, such as requiring special ingress and egress internet filters, specific forms of endpoint protection, or similar.
Pipelines and agents with different levels of sensitivity should always be separated by a security boundary. These security boundaries ensure that untrusted or less-trusted code cannot leak more sensitive data. This is especially important when regulatory requirements are involved, but it’s also a good idea to follow best practices wherever possible.
If this is especially important to your organization, check out our Continuous compliance and governance in CI/CD post. In the post, Mel describes how to design your CI/CD workflows with compliance and governance measures in mind.
Enforcing boundaries in practice
How you enforce security boundaries depends on your particular CI/CD system. At Buildkite, we’ve done a lot of thinking about security and secrets—we’ll present general advice and talk to Buildkite specifics to help ground the explanations.
First, think about security boundaries. That is, mechanisms designed to enforce separation for security reasons rather than to help you organize elements. Buildkite has a few key mechanisms:
- Clusters are distinct security boundaries. Pipelines in one cluster can’t interact with those in a separate one, and users/groups can be assigned maintainer access on specific clusters.
- Queues help you organize agents into groups inside your clusters. Pipelines target a specific queue and run on the agents attached to that queue.
- Tags provide a way to target individual agents.
Of those three methods, clusters are the only ones designed to create a security boundary. They’re also useful for general organization—but for access and sensitivity concerns, this is the mechanism to use.
In the security case, each cluster is assigned a particular security level, amount of access to systems, etc. These match the way the engineers think about and assign access internally, as well as how the security boundaries are defined. Here are some of the ways we’ve seen clusters be defined:
- Dev, Test, Production.
- Open Source, Internal.
- One cluster per project.
Since queues don’t create a security boundary, a utility-based breakdown like size, platform, and architecture is more common (for example, small_mac_silicon). Queues help organize which types of agents to use inside the security boundary. In the same way, tags let you reserve or target agents in a more specific way (for example, xyz_builder), but this should also not be thought of as a security measure.
The hosting option your CI/CD system uses also applies here. Managed CI/CD means a third party always has access to some secrets like your source code. Alternatively, self-hosted or hybrid options mean you can choose how restricted these secrets are depending on your needs. Refer to Managed, self-hosted, or hybrid CI/CD? Understand your options for an in-depth discussion of this topic.
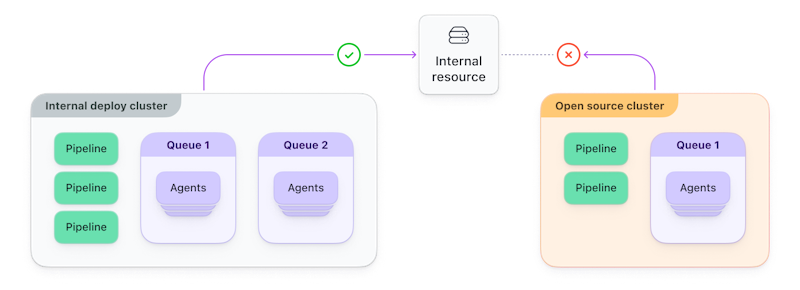
Example: Balancing open source
We mentioned some risks associated with running open-source projects alongside your private projects. Well, clusters can help mitigate those risks. Rather than running CI/CD on shared agents, you can create separate clusters for open-source and closed-source projects. You can configure agents in each cluster with different access to internal systems and secrets.
Example: Fine-grained administration
Picture a situation where one team in your organization wants to manage their own CI/CD infrastructure. That team would like to maintain queues, create agents and add them to their queues, and more.
In Buildkite, you can add users and teams as maintainers of a cluster. Maintainers can manage queues within the cluster, add or remove pipelines from the cluster, and also create agent tokens that are used to connect to the cluster. For example, the following diagram shows that users MB and DO can maintain Cluster A, and users DO, MK, and GG can maintain Cluster B.
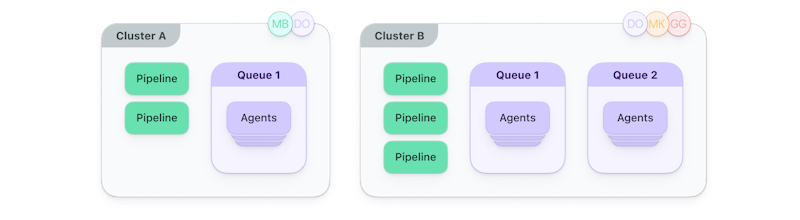
Each cluster has a set of pipelines and queues of agents to run builds for the pipelines. By assigning maintainers, you can give teams more control over the queues and agents running their pipelines without impacting other projects.
Example: Dealing with a sensitive product
Imagine this: You have an existing organization with a couple of open-source projects and various internal products. Production access and pipelines are limited appropriately, and users can only see the projects they’re a part of.
But your team is developing a brand new product for a regulated industry with compliance requirements that are complex to implement and slow down your workflow.
In practical terms, these requirements mean:
- Extra CPU usage for compliant hosts.
- Compliant hosts have no interaction with non-compliant software and hardware.
Importantly, it’s a tough set of regulations that you don’t want your core products or development process to have to comply with.
Buildkite’s clusters let you create these distinct boundaries. You can create a new cluster to house the new product, and ensure all agents and pipelines in that cluster fulfill the regulatory needs.
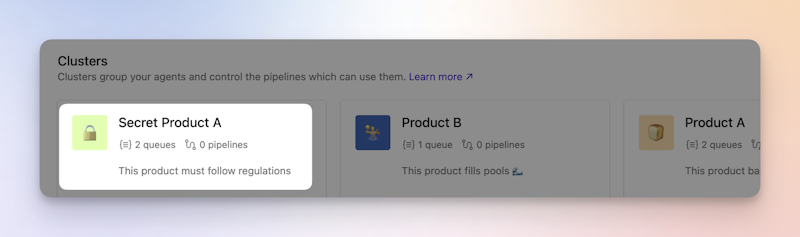
From there, your agents (configured according to any regulatory requirements) are added with agent tokens, scoped to the cluster itself, and potentially restricted by IP address. On joining, agents are associated with a queue in the cluster.
Finally, you can use queues, tags, build matrices, and all the other features Buildkite Pipelines makes available, knowing everything is inside a security boundary and separate from your other pipelines and agents.
Example: Reserving agents for specific jobs
Stepping away from security boundaries for a moment, the following example shows you how to use another boundary mechanism to organize your agents.
Let’s say you have ten agents that trigger builds on external machines and then upload the artifacts. Due to the number of build servers available, you need to ensure the agents are set up in the following way:
- Six Windows build agents
- Two macOS build agents
- Two Linux build agents
We’re not working with security boundaries but instead, boundaries that help us organize. For this reason, we’re using agent tags, as they are most appropriate for arbitrary agent targeting. We can keep everything in a single queue in this example:
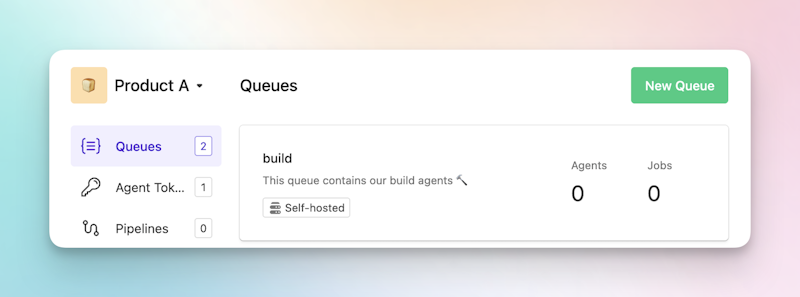
Agent tags are set when the agent is created, and the same tag name can have different values on different agents. For this example, we’ll use the tag name target and have the value be the OS being built for—so target=Windows, target=macOS, and target=Linux.
Once you’ve launched your agents, they will appear in the queue you’ve assigned:
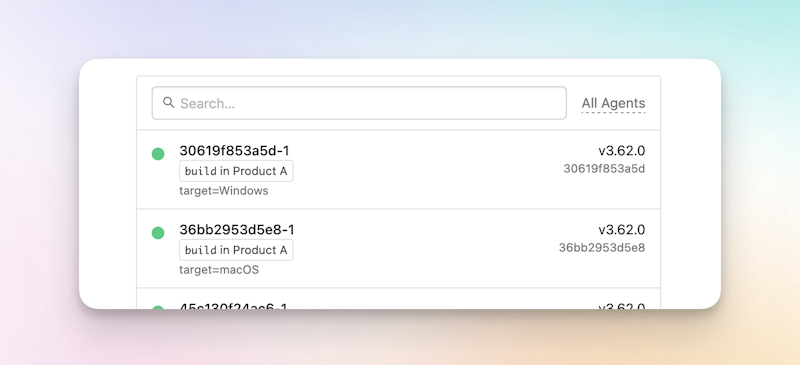
From here, you can simply specify the target name in the agent targeting section of your pipeline definition:
steps:
- command: "script.sh"
agents:
target: 'Windows'This becomes very exciting when you think about updating the pipeline definition at runtime using dynamic pipelines and how you could use the build meta-data to get the current build target.
Conclusion
Security boundaries are an important tool for protecting your CI/CD pipelines. In addition, the principles of least privilege, zero trust, and isolating infrastructure with different sensitivities are vital to creating a safe and secure software engineering environment.
You can create security boundaries with any CI/CD tool—at Buildkite, we use clusters as our strong security boundaries, with queues and tags available for agent grouping and targeting.
If you’d like to read more about CI/CD risks and security practices, check out the following resources:
Buildkite Pipelines is a CI/CD tool designed for developer happiness. Easily follow and decipher logs, get observability into key build metrics, and tune for enterprise-grade speed, scale, and security. Every new signup gets a free 30-day trial to test out the key features. See Buildkite Pipelines to learn more.